
INTRODUCTION
先日、Kotlinの学習としてAndroidアプリの三目並べを作成した。しかしコンピュータの思考ルーチンが遅く、ウリである四目、五目並べが激弱になってしまった。
そこでAIを使ったら強くならないか?と考え、その実装を目指してみる。
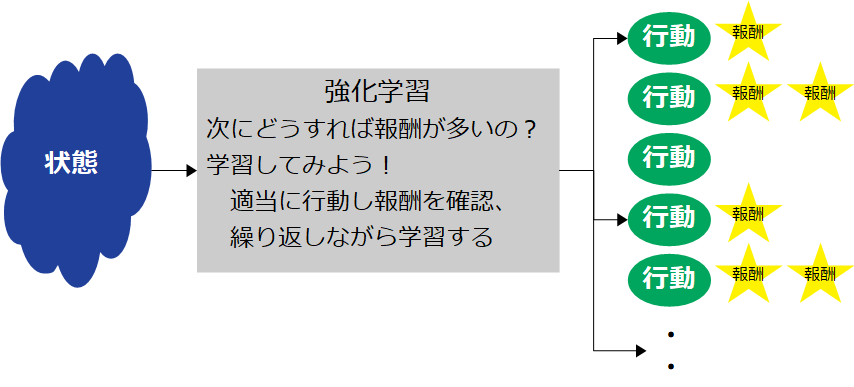
強化学習
三目並べで最善手を打つために、プログラム自身で学習する。学習方法は「強化学習」と呼ばれるもので、ある状態から最大の報酬を得るための行動を学習する。
Q学習
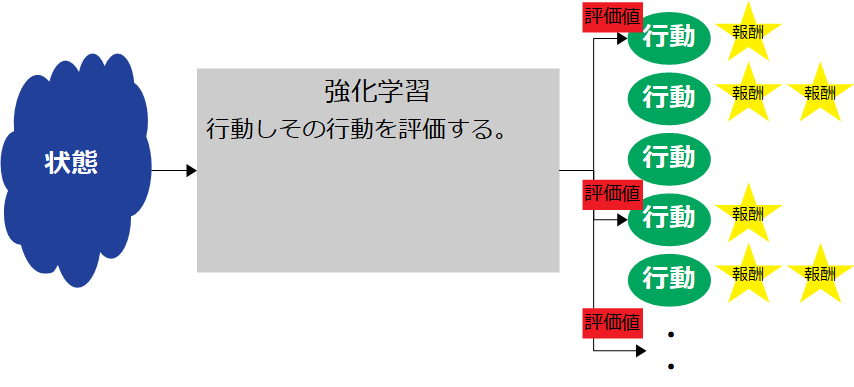
強化学習の方法は複数ある。その中でオーソドックスな「Q学習」を行ってみる。ある状態の時にどの行動をとればいいか、それは状態毎の各行動に評価値を算定することで実現できる。この算定方法の一つがQ学習だ。
Q学習の評価値は次式により算定する。
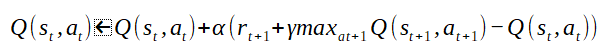
※ここで、ブラウザのタブを閉じようとしているなら待ってください。このような数式、初めて入力するレベルですが超訳します!
Qテーブル
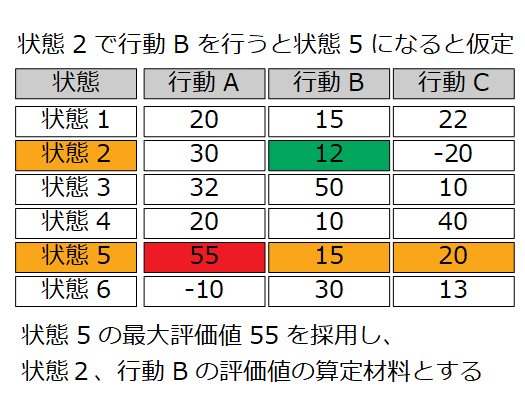
数式を理解する前に評価値を入れる表をイメージする。縦に状態、横に行動の表だ。
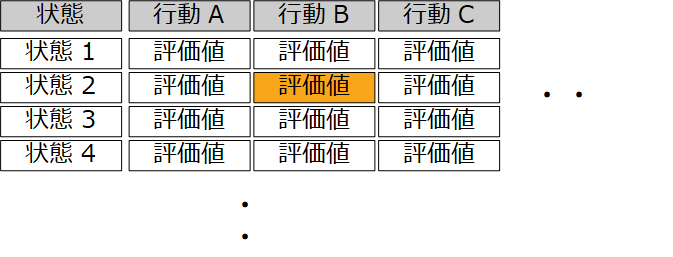
例えば状態2の時に行動Bを行う。この行、列の該当箇所が評価値だ。
式を超訳
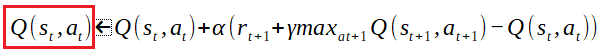
Q(st,at)は上記テーブル指す。stが特定の状態、atが特定行動を意味し、Q(st,at)でその評価値を示している。プログラミング言語の二次元配列、Q[特定行][特定列]というように考えればスッキリする。

「<-」の右辺が新たな評価値となる。
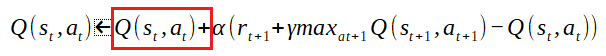
新たな評価値は、元の評価値(Q(st,at))に足しこみ計算する。さらに右辺をみていく。
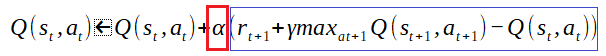
「α」は学習率と言われ1回の学習の重みを表している。つまり1回の学習でその影響度を大きくしたい場合はα値を大きくする。範囲は0<α<=1で一般的に0.1が用いられる。

「rt+1」は報酬である。三目並べなら勝利した場合は10、敗北した場合-10、それ以外は0などの報酬を設定する。
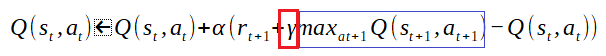
行動の評価値は前の行動に起因する。とは言え次の行動の評価値をそのまま前の行動の評価値には採用できない。なぜなら前の行動が全ての要因ではないからだ。そこで割り引いて利用する。この割引率が「γ」だ。範囲は0<γ<=1で一般的に0.9前後を設定する。
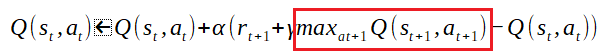
次の行動の評価値を算定に利用する。その際に最も有効な手(評価値が高い)を採用する。これが「maxat+1Q(st+1,at+1)」の記述だ。
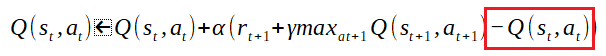
最後に現在評価値で減算している…謎である。実はこの数式は下記を展開したものである。
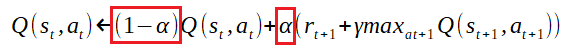
現在値と学習で得る値をα(学習率)の割合で按分している。展開後の数式「-Q(st,at)」はこの按分を表現しているのだ。
少しロジックがわかってきた。これを三目並べで学習するようにプログラミングすればいいだけだが、、、完成はいつになることやら・・・
ーーー>つづく