
学習します!
いよいよQ学習を行っていく。100万回試合させるため、クラスMainに次のコードを記述した。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
win = [0] * 3 ran =1000000 #試行回数 start_time = time.time() player = [self.playerrandom,self.playerai] #対戦プレイヤー設定 [先攻、後攻] for i in range(ran): #試行ループ greedy = Const.GREEDY * (ran-i) / ran #AIのランダム手数の確立を徐々に下げる ret = self.play(player,greedy) #対戦 play[先手,後手] self.kiban.clear(Const.BANSU) if player[0].whois() == Const.HUMAN or player[1].whois() == Const.HUMAN: if ret == Const.EXIT: #人の指示により強制終了 break print(Const.MSG[ret]) #人対戦の時の結果を表示 win[ret] += 1 if (i+1) % 10000 == 0: comp = str((win[2] / (i+1))*100) print(str(i+1)+"回:先攻勝:"+str(win[1])+" 後攻勝:"+str(win[2])+" 引分け:"+str(win[0])+" 後攻勝率:" +comp) |
5行目で対戦相手を決めている。ランダムに打つコンピュータが先攻、学習を行うAIが後攻だ。これでゲーム関数play()を100万回呼び出せばいいのだが、AIプレイヤーがランダムに打つ確率(学習範囲を狭めないため)を最初は高くし、学習が進むにつれ低くしている。それが8行目だ。
学習率、割引率等は次の値を設定している。
|
1 2 3 |
GAKUSYU = 0.1 #学習率 WARIBIKI = 0.9 #割引率 GREEDY = 0.2 #AIがランダムに打つ初期割合 |
結果
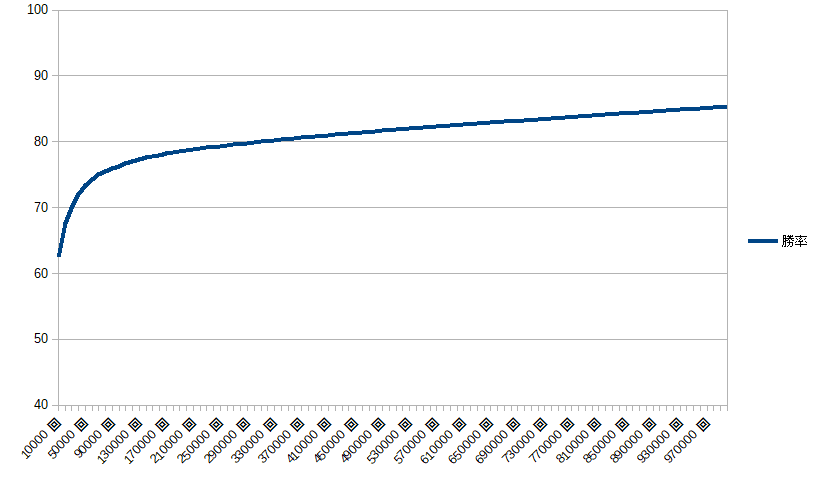
100万回試合でAIの勝率は85%ほどだった。低いような気がする・・・。グラフにしてみた。
試合を行う毎に少しずつ勝率が上がっている。学習効果が出ているとみてよさそうだ。
ここまでのソースコードを掲載する。
忘れていた!「目的」
これで完了したと喜んでいたが、すっかり目的を忘れていた。
Androidアプリで三目並べを作ったが三目並べでは思考ルーチン(ミニマックス法)に問題はなかった。しかしウリである四目、五目並べでは思考ルーチンが遅く激弱だったのだ。そこでAI使うことを思いついた。
ここから四目、五目並べにして学習させていけばいいのだが・・・まだまだ道のりは遠そうである。
前へ<ーーー>とりあえず完