

ゲームコントロール
三目並べエンジン、Q値管理、各プレイヤープログラムと部品は揃った。あとはこれらを制御しながらQ学習を行っていけばよい。クラスMainにplay()関数を実装した。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
"""ゲームメイン処理 """ def play(self,players,greedy): #ゲーム state = True #先攻:Ture、後攻:False count = 0 #打ち手回数 isExit = False exit_status = 0 key = [0] * 2 #状態情報、[0]:先攻 [1]:後攻 xy = np.zeros((2,2),dtype=int) #打ったX,Y座標用。これから状態のQ値を求める win = 0 while True: #ゲーム終了までループ for idx,player in enumerate(players): #先攻、後攻交互にループ key[idx] = self.kiban.kibanToString() #棋盤情報から状態情報へ変換し格納 ret = player.play(self.kiban,self.qtable,greedy)#手を考える if not ret: #人用 強制終了したいなら exit_status = Const.EXIT isExit = True break xy[idx] = ret kigou = Const.BATU if state else Const.MARU #先攻、後攻用のマーク(×、○)を取得 self.kiban.setKiban(xy[idx][0],xy[idx][1],kigou) #棋盤に手を打つ if players[0].whois() == Const.HUMAN or players[1].whois() == Const.HUMAN: #人対戦なら棋盤表示 self.kiban.disp() if player.whois() != Const.AI: #AIでないなら手を打った後の状態情報を格納する key[idx] = self.kiban.kibanToString() exit_status = self.kiban.checkFinal(xy[idx][0],xy[idx][1]) #勝敗判定 if exit_status != Const.KUHAKU: #勝敗が決まった? if player.whois() == Const.AI: win = Const.WIN_VALUE #勝ち報酬 else: win = Const.LOSS_VALUE #負けペナルティ isExit = True state = not state #手番を変更 count += 1 #手数をカウントアップ if count >= Const.BANSU * Const.BANSU: #打つ手が無くなった? win = Const.DRAW_VALUE isExit = True if isExit == True: #終了 if player.whois() == Const.AI: #勝負が決まった。AIが打った Q値更新 self.qtable.cal(key[idx],0,xy[idx][0],xy[idx][1],win) else: #勝負が決まった。AI以外が打った Q値更新 self.qtable.cal(key[abs(idx-1)],0,xy[abs(idx-1)][0],xy[abs(idx-1)][1],win) break if player.whois() != Const.AI and count != 1: #未決着 AIや一手目(次の手がない)以外ならQ値更新 self.qtable.cal(key[abs(idx-1)],key[idx],xy[abs(idx-1)][0],xy[abs(idx-1)][1],win) if isExit==True: break return exit_status |
呼び出し方法
この関数は次の形式で呼び出す。
対戦するプレイヤークラスのインスタンスを配列にし第一引数に設定する。配列の0番目が先攻、1番目が後攻である。第二引数はAIプレイヤーがランダムな手を打つ確率だ。
関数を呼び出すとゲーム終了まで実行される。
プログラム構造
プログラムの構造は次のようなイメージだ。

一見単純な構造のようだが、ここが難解であった。Q値は「ある状態の時に次の行動を行った際の評価値」だ。そしてその評価値の算定に「次の手の最も高いQ値」を利用する。従ってAIプレイヤー、次の手(他プレイヤー)の状態がないとQ値を算定できない。
当初は次のイメージでQ値を更新していた。
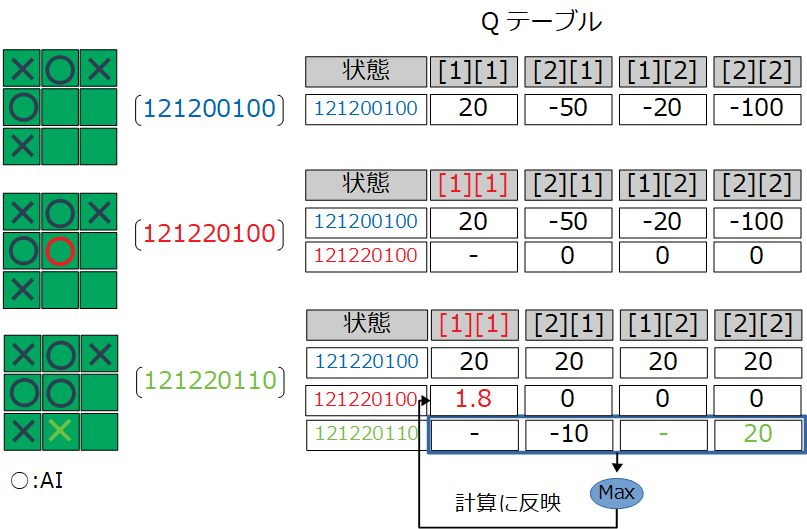
これはあきらかに間違いだ。ある状態の行動を評価しなければいけないので、図の状態「121220100」の行動[1][1]が対象となる。正しくは次のイメージで更新しなければいけなかった。
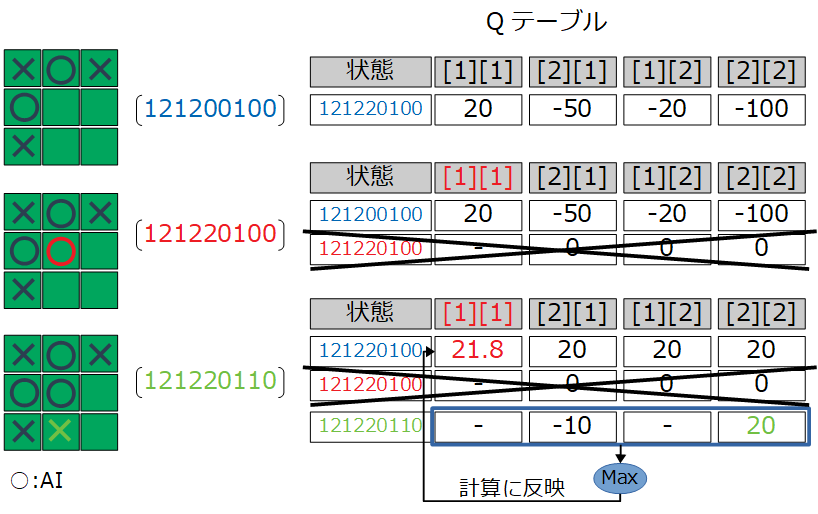
これを実現するためプログラムではAIプレイヤー、その他プレイヤーの状態情報の格納タイミングが違ってきている(下記3行目がAI、7行目がその他プレイヤー用)
|
1 2 3 4 5 6 7 8 9 10 |
while True: #ゲーム終了までループ for idx,player in enumerate(players): #先攻、後攻交互にループ key[idx] = self.kiban.kibanToString() #棋盤情報から状態情報へ変換し格納 ・ self.kiban.setKiban(xy[idx][0],xy[idx][1],kigou) #棋盤に手を打つ ・ if player.whois() != Const.AI: #AIでないなら手を打った後の状態情報を格納する key[idx] = self.kiban.kibanToString() ・ ・ |
これでゲームを行い、Q学習することができる。あとは膨大な学習(試合)を行うように、この関数を何万回も呼び出すようにすればよい。